* 데이터 처리를 위한 기본 정보
1. 기본 데이터 타입 ( Basic Type )
logical
|
논리 값, T or True, F or False
|
numeric
|
수치 값, duble, numeric, real
(double-precision)
|
integer
|
정수 값
|
character
|
문자 값, 인용부호로 표기된 것
|
complex
|
복소수 값
|
raw
|
Bytes 값
|
R의 typeof(), mode(), storage.mode() 함수를 사용하여 기본데이터 타입을 체크/확인 할 수 있음
typeof
|
mode
|
storage.mode
|
logical
|
logical
|
logical
|
inetger
|
numeric
|
inetger
|
double
|
numeric
|
double
|
complex
|
complex
|
complex
|
character
|
character
|
character
|
2. 특수한 값
NA : 결측치 (Missing Value)
NaN : 부정(Not a Number), 어떤 값을 0으로 나눈 것
Inf, -Inf : 무한대 (infinite), 양의 무한대, 음의 무한대
NULL : 정의되지 않은 값
쓰다보면 정해진 상수를 사용하는 경우가 있음
pi : 원주율
LETTERS : "A"부터 "Z" 까지의 26개 대문자 알파벳 백터
letters : "a"부터 "z" 까지의 26개 소문자 알파벳 백터
month.abb : "Jan" 부터 "Dec" 까지의 12개월을 나타내는 약어 벡터
month.name : "January" 부터 "December" 까지의 12개월을 나타내는 이름 벡터
3. 데이터 객체
Vector(벡터) - 동일한 기본 데이터 타입으로 구성된 순서가 있는 데이터 구조이며 수학적인 의미의 벡터 이상의 기능이 있어서 문자 값이나 논리 값을 원소로 가질 수 있다.
Matrix(행렬) - 동일한 데이터 모드로 구성된 사각형 구조의 값들이 집합으로 수학에서 행렬을 표현할 수 있다.
Arrary(배열) - 동일한 데이터 모드로 구성된 배열 구조의 값들의 집합으로 행렬은 2차원 배열이라 할 수 있다.
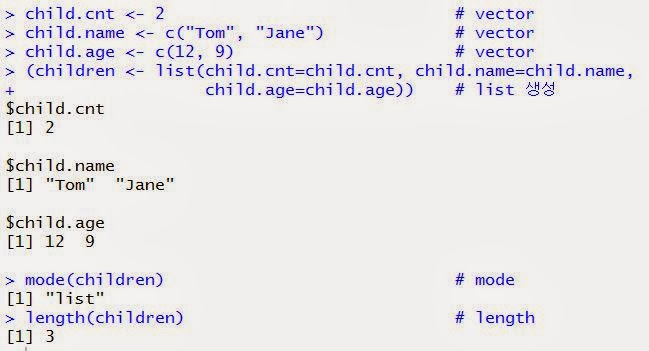
List(리스트) - 데이터 모드가 다른 데이터들을 표현할 수 있는데 Component라고 불리는 각기 다른 데이터 객체로 구성된 데이터 구조체 이다.
Factor - 통계학에서 Categorical Data(범주형 데이터)인 명목척도와 서열척도를 표현하는 데이터 객체로 벡터의 특수한 형태라고 할 수 있다.
Data Frame(데이터프레임) - 일반적인 data set (데이터셋)을 표현하며, 데이터베이스 시스템의 테이블과 유사한 구조이다. 한개 이상의 변수로 구성되며, 각각의 변수의 모드는 같거나 다를 수 있다.
4. Data Import and Export ( Included R Data Save )
외부에 있는 데이터를 읽어 오게 되는 경우가 대부분 일 것이다. 간단하게 테스트 하는 형태로는 엑셀 파일이나 CSV, TEXT 파일 등일수 있으나 RDB로 부터 직접 읽어 드리는 방법도 존재 한다. 이번 포스팅에서는 간단한 형태의 파일을 읽어 오고 내보내는 기능을 보고 향후 포스팅에서 Oracle Database 를 직접 연결하여 가져오는 방법을 공유하도록 한다.
R Studio - Windows 64Bit 환경 에서 테스트 하였음. 작업을 하다 보면 첨부 이미지와 같이 변수 데이터 들이 저장되어 있음을 볼 수 있다.
# R Studio Image Save
save.image("~/rSample/R_Book/Example_20140225.RData")
# R Studio Image Load
load("~/rSample/R_Book/Example_20140225.RData")
## Oracle Data Import
# Packages Install
install.packages("RODBC")
install.packages("sqldf")
install.packages("tcltk")
# Library Load
library(RODBC)
library(sqldf)
library(tcltk)
#Channel Setting
#channel <- odbcConnect("TNS 설정이름", uid="DB접속아이디", pwd="접속패스워드", believeNRows=FALSE)
channel <- odbcConnect("REAL", uid="USER_ID", pwd="PASSWD", believeNRows=FALSE)
#Data Load
tSales <- sqlQuery(channel, "select sdate, sales_amt from dual")
str(tSales)
summary(tSales)
## 이 글은 " R을 이용한 통계학의 이해(자유아카데미) " 내용 중 일부를 발췌하였고 개인이 직접 추가한 자료를 포함 하고 있음을 알린다.
## 구매 자유아카데미 출판사 사이트
이곳을 클릭하여 연결