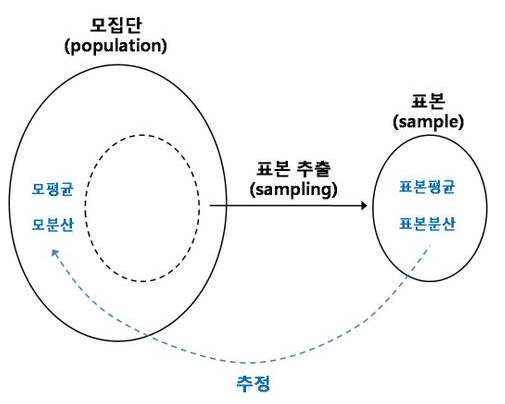
#1 - 변수 값 할당
##대입연산자 <- 단축키 ( Alt + - )
a <- 1
x <- 3
print(a)
## [1] 1
print(x)
## [1] 3
#2 - 변수를 출력하는 방식 - print()
x <- c("TR", "MG", "SH", "KR")
print(x)
## [1] "TR" "MG" "SH" "KR"
#3 - 변수 연산
print(c(1*pi, 2*pi, 3*pi, 4*pi))
## [1] 3.142 6.283 9.425 12.566
#4 - 변수 논리값
c(TRUE, FALSE, TRUE, FALSE)
## [1] TRUE FALSE TRUE FALSE
c(true, false, true)
## Error: 객체 'true'를 찾을 수 없습니다
#5 - 변수 결합
v1 <- c(1, 2, 3)
v2 <- c(4, 5, 6)
v3 <- c(v1, v2)
v3
## [1] 1 2 3 4 5 6
#6 - 수열
1:5
## [1] 1 2 3 4 5
b <- 2:10
b
## [1] 2 3 4 5 6 7 8 9 10
10:19
## [1] 10 11 12 13 14 15 16 17 18 19
19:10
## [1] 19 18 17 16 15 14 13 12 11 10
e <- 10:2
e
## [1] 10 9 8 7 6 5 4 3 2
#7 - seq(from=시작점, to=끝점, by=간격)
seq(from=0, to=20, by=2)
## [1] 0 2 4 6 8 10 12 14 16 18 20
seq(from=0, to=20, length.out=5)
## [1] 0 5 10 15 20
# 소수점의 표기가 있는 경우
seq(from=1.0, to=20.0, length.out=5)
## [1] 1.00 5.75 10.50 15.25 20.00
seq(0, 20, by=2)
## [1] 0 2 4 6 8 10 12 14 16 18 20
seq(0, 10, length=20)
## [1] 0.0000 0.5263 1.0526 1.5789 2.1053 2.6316 3.1579 3.6842
## [9] 4.2105 4.7368 5.2632 5.7895 6.3158 6.8421 7.3684 7.8947
## [17] 8.4211 8.9474 9.4737 10.0000
#8 - rep(반복할 내용, 반복할 수)
rep(1, time=5)
## [1] 1 1 1 1 1
rep(1:2, each=2)
## [1] 1 1 2 2
c <- 1:5
c
## [1] 1 2 3 4 5
rep(c,5)
## [1] 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
rep(c, each=5)
## [1] 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 4 4 4 4 4 5 5 5 5 5
#9 - paste(" 붙일 내용붙일 내용 " , sep= '''')
A <- c( " a" , "b" , "c")
A
## [1] " a" "b" "c"
paste( "a" , "b" , sep="")
## [1] "ab"
paste(A , c("d", "e"))
## [1] " a d" "b e" "c d"
f <- paste( A, 10)
f
## [1] " a 10" "b 10" "c 10"
paste(A , 10, sep= "")
## [1] " a10" "b10" "c10"
paste(A,1: 10, sep="_" )
## [1] " a_1" "b_2" "c_3" " a_4" "b_5" "c_6" " a_7" "b_8"
## [9] "c_9" " a_10"
paste("Everybody" , "loves" , "cats.")
## [1] "Everybody loves cats."
#10 - Substr(문자열 , 시작, 끝)
substr ("BigDat aAnalys i s" , 1,4)
## [1] "BigD"
ss <- c( "Moe ", "Larry", "Cur ly")
substr (ss , 1, 3)
## [1] "Moe" "Lar" "Cur"
#11 - 논리값 & 논리연산자
a <- 3
a == pi
## [1] FALSE
a != pi
## [1] TRUE
a < pi
## [1] TRUE
a <= pi
## [1] TRUE
a > pi
## [1] FALSE
a >= pi
## [1] FALSE
#12 - Matrix
# matrix( 이름, 행 수, 열 수)
# dim() 행렬의 행과 열 수를 반환
theData<- c(1.1, 1.2, 2.1, 2.2, 3.1,3.2)
mat<-matrix(theData ,2, 3)
mat
## [,1] [,2] [,3]
## [1,] 1.1 2.1 3.1
## [2,] 1.2 2.2 3.2
dim(mat)
## [1] 2 3
diag(mat)
## [1] 1.1 2.2
#diag( 행렬) 행렬의 대 각선 에 있는 값을 반환
#t() Matrix Transpose
t(mat)
## [,1] [,2]
## [1,] 1.1 1.2
## [2,] 2.1 2.2
## [3,] 3.1 3.2
help(t)
## starting httpd help server ... done
# colnamesO 열 네임을 조회
# rownamesO 행 네임을 조회
mat
## [,1] [,2] [,3]
## [1,] 1.1 2.1 3.1
## [2,] 1.2 2.2 3.2
colnames(mat) <- c(" IBM" , "MS", "GOOGLE" )
rownames(mat) <- c( "IBM" , "MS")
mat[1,] #첫째 행
## IBM MS GOOGLE
## 1.1 2.1 3.1
mat[,3] #셋째 열
## IBM MS
## 3.1 3.2
A <- matrix(0, 4,5)
A <- matrix(1:20 ,4, 5)
A
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 5 9 13 17
## [2,] 2 6 10 14 18
## [3,] 3 7 11 15 19
## [4,] 4 8 12 16 20
#1행, 4행, 2열, 3열 조회
A[c(1, 4), c(2, 3)]
## [,1] [,2]
## [1,] 5 9
## [2,] 8 12
#값을 대체
A[c(1 , 4) , c(2 ,3)] <- 1
#13 - List() 리스트에서 원소들은 다른 모드
lst <- list(3.14, "Mode", c(1 , 1.2, 3), mean)
lst
## [[1]]
## [1] 3.14
##
## [[2]]
## [1] "Mode"
##
## [[3]]
## [1] 1.0 1.2 3.0
##
## [[4]]
## function (x, ...)
## UseMethod("mean")
## <bytecode: 0x00000000085711a0>
## <environment: namespace:base>
a <-1:10
b <- matrix(1:10, 2, 5)
c <- c("name1", "name2")
alst <- list(a=a , b=b , c=c)
alst
## $a
## [1] 1 2 3 4 5 6 7 8 9 10
##
## $b
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 3 5 7 9
## [2,] 2 4 6 8 10
##
## $c
## [1] "name1" "name2"
str(alst)
## List of 3
## $ a: int [1:10] 1 2 3 4 5 6 7 8 9 10
## $ b: int [1:2, 1:5] 1 2 3 4 5 6 7 8 9 10
## $ c: chr [1:2] "name1" "name2"
alst$a
## [1] 1 2 3 4 5 6 7 8 9 10
alst$b
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 3 5 7 9
## [2,] 2 4 6 8 10
alst$c
## [1] "name1" "name2"
alst[[1]]
## [1] 1 2 3 4 5 6 7 8 9 10
alst[[1]][[2]]
## [1] 2
#14 - Dataframe
a <- c(1 , 2, 4, 6, 3,4)
b <- c(6 , 4 , 2, 4, 3.2 , 4)
c <- c(7 , 6 , 4, 2, 5,6)
d <- c(2 , 4 , 3, 1, 5, 6)
e <- data.frame(a , b, c, d)
e
## a b c d
## 1 1 6.0 7 2
## 2 2 4.0 6 4
## 3 4 2.0 4 3
## 4 6 4.0 2 1
## 5 3 3.2 5 5
## 6 4 4.0 6 6
# rbind(dfrml, dfrm2) 두 데이터 프레임의 행을 추가 할 때 사용
# cbind(dfrml, dfrm2) 두 데이터 프레임의 열을 추가 할 때 사용
data(iris)
head(iris)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
newRow <- data.frame (Sepal.Length=3.0, Sepal.Width=3.2, Petal.Length=1.6, Petal.Width=0.3, Species="newsetosa")
newRow
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 3 3.2 1.6 0.3 newsetosa
iris <- rbind(iris , newRow)
iris
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5.0 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## 11 5.4 3.7 1.5 0.2 setosa
## 12 4.8 3.4 1.6 0.2 setosa
## 13 4.8 3.0 1.4 0.1 setosa
## 14 4.3 3.0 1.1 0.1 setosa
## 15 5.8 4.0 1.2 0.2 setosa
## 16 5.7 4.4 1.5 0.4 setosa
## 17 5.4 3.9 1.3 0.4 setosa
## 18 5.1 3.5 1.4 0.3 setosa
## 19 5.7 3.8 1.7 0.3 setosa
## 20 5.1 3.8 1.5 0.3 setosa
## 21 5.4 3.4 1.7 0.2 setosa
## 22 5.1 3.7 1.5 0.4 setosa
## 23 4.6 3.6 1.0 0.2 setosa
## 24 5.1 3.3 1.7 0.5 setosa
## 25 4.8 3.4 1.9 0.2 setosa
## 26 5.0 3.0 1.6 0.2 setosa
## 27 5.0 3.4 1.6 0.4 setosa
## 28 5.2 3.5 1.5 0.2 setosa
## 29 5.2 3.4 1.4 0.2 setosa
## 30 4.7 3.2 1.6 0.2 setosa
## 31 4.8 3.1 1.6 0.2 setosa
## 32 5.4 3.4 1.5 0.4 setosa
## 33 5.2 4.1 1.5 0.1 setosa
## 34 5.5 4.2 1.4 0.2 setosa
## 35 4.9 3.1 1.5 0.2 setosa
## 36 5.0 3.2 1.2 0.2 setosa
## 37 5.5 3.5 1.3 0.2 setosa
## 38 4.9 3.6 1.4 0.1 setosa
## 39 4.4 3.0 1.3 0.2 setosa
## 40 5.1 3.4 1.5 0.2 setosa
## 41 5.0 3.5 1.3 0.3 setosa
## 42 4.5 2.3 1.3 0.3 setosa
## 43 4.4 3.2 1.3 0.2 setosa
## 44 5.0 3.5 1.6 0.6 setosa
## 45 5.1 3.8 1.9 0.4 setosa
## 46 4.8 3.0 1.4 0.3 setosa
## 47 5.1 3.8 1.6 0.2 setosa
## 48 4.6 3.2 1.4 0.2 setosa
## 49 5.3 3.7 1.5 0.2 setosa
## 50 5.0 3.3 1.4 0.2 setosa
## 51 7.0 3.2 4.7 1.4 versicolor
## 52 6.4 3.2 4.5 1.5 versicolor
## 53 6.9 3.1 4.9 1.5 versicolor
## 54 5.5 2.3 4.0 1.3 versicolor
## 55 6.5 2.8 4.6 1.5 versicolor
## 56 5.7 2.8 4.5 1.3 versicolor
## 57 6.3 3.3 4.7 1.6 versicolor
## 58 4.9 2.4 3.3 1.0 versicolor
## 59 6.6 2.9 4.6 1.3 versicolor
## 60 5.2 2.7 3.9 1.4 versicolor
## 61 5.0 2.0 3.5 1.0 versicolor
## 62 5.9 3.0 4.2 1.5 versicolor
## 63 6.0 2.2 4.0 1.0 versicolor
## 64 6.1 2.9 4.7 1.4 versicolor
## 65 5.6 2.9 3.6 1.3 versicolor
## 66 6.7 3.1 4.4 1.4 versicolor
## 67 5.6 3.0 4.5 1.5 versicolor
## 68 5.8 2.7 4.1 1.0 versicolor
## 69 6.2 2.2 4.5 1.5 versicolor
## 70 5.6 2.5 3.9 1.1 versicolor
## 71 5.9 3.2 4.8 1.8 versicolor
## 72 6.1 2.8 4.0 1.3 versicolor
## 73 6.3 2.5 4.9 1.5 versicolor
## 74 6.1 2.8 4.7 1.2 versicolor
## 75 6.4 2.9 4.3 1.3 versicolor
## 76 6.6 3.0 4.4 1.4 versicolor
## 77 6.8 2.8 4.8 1.4 versicolor
## 78 6.7 3.0 5.0 1.7 versicolor
## 79 6.0 2.9 4.5 1.5 versicolor
## 80 5.7 2.6 3.5 1.0 versicolor
## 81 5.5 2.4 3.8 1.1 versicolor
## 82 5.5 2.4 3.7 1.0 versicolor
## 83 5.8 2.7 3.9 1.2 versicolor
## 84 6.0 2.7 5.1 1.6 versicolor
## 85 5.4 3.0 4.5 1.5 versicolor
## 86 6.0 3.4 4.5 1.6 versicolor
## 87 6.7 3.1 4.7 1.5 versicolor
## 88 6.3 2.3 4.4 1.3 versicolor
## 89 5.6 3.0 4.1 1.3 versicolor
## 90 5.5 2.5 4.0 1.3 versicolor
## 91 5.5 2.6 4.4 1.2 versicolor
## 92 6.1 3.0 4.6 1.4 versicolor
## 93 5.8 2.6 4.0 1.2 versicolor
## 94 5.0 2.3 3.3 1.0 versicolor
## 95 5.6 2.7 4.2 1.3 versicolor
## 96 5.7 3.0 4.2 1.2 versicolor
## 97 5.7 2.9 4.2 1.3 versicolor
## 98 6.2 2.9 4.3 1.3 versicolor
## 99 5.1 2.5 3.0 1.1 versicolor
## 100 5.7 2.8 4.1 1.3 versicolor
## 101 6.3 3.3 6.0 2.5 virginica
## 102 5.8 2.7 5.1 1.9 virginica
## 103 7.1 3.0 5.9 2.1 virginica
## 104 6.3 2.9 5.6 1.8 virginica
## 105 6.5 3.0 5.8 2.2 virginica
## 106 7.6 3.0 6.6 2.1 virginica
## 107 4.9 2.5 4.5 1.7 virginica
## 108 7.3 2.9 6.3 1.8 virginica
## 109 6.7 2.5 5.8 1.8 virginica
## 110 7.2 3.6 6.1 2.5 virginica
## 111 6.5 3.2 5.1 2.0 virginica
## 112 6.4 2.7 5.3 1.9 virginica
## 113 6.8 3.0 5.5 2.1 virginica
## 114 5.7 2.5 5.0 2.0 virginica
## 115 5.8 2.8 5.1 2.4 virginica
## 116 6.4 3.2 5.3 2.3 virginica
## 117 6.5 3.0 5.5 1.8 virginica
## 118 7.7 3.8 6.7 2.2 virginica
## 119 7.7 2.6 6.9 2.3 virginica
## 120 6.0 2.2 5.0 1.5 virginica
## 121 6.9 3.2 5.7 2.3 virginica
## 122 5.6 2.8 4.9 2.0 virginica
## 123 7.7 2.8 6.7 2.0 virginica
## 124 6.3 2.7 4.9 1.8 virginica
## 125 6.7 3.3 5.7 2.1 virginica
## 126 7.2 3.2 6.0 1.8 virginica
## 127 6.2 2.8 4.8 1.8 virginica
## 128 6.1 3.0 4.9 1.8 virginica
## 129 6.4 2.8 5.6 2.1 virginica
## 130 7.2 3.0 5.8 1.6 virginica
## 131 7.4 2.8 6.1 1.9 virginica
## 132 7.9 3.8 6.4 2.0 virginica
## 133 6.4 2.8 5.6 2.2 virginica
## 134 6.3 2.8 5.1 1.5 virginica
## 135 6.1 2.6 5.6 1.4 virginica
## 136 7.7 3.0 6.1 2.3 virginica
## 137 6.3 3.4 5.6 2.4 virginica
## 138 6.4 3.1 5.5 1.8 virginica
## 139 6.0 3.0 4.8 1.8 virginica
## 140 6.9 3.1 5.4 2.1 virginica
## 141 6.7 3.1 5.6 2.4 virginica
## 142 6.9 3.1 5.1 "aperm" virginica
## 143 5.8 2.7 5.1 1.9 virginica
## 144 6.8 3.2 5.9 2.3 virginica
## 145 6.7 3.3 5.7 2.5 virginica
## 146 6.7 3.0 5.2 2.3 virginica
## 147 6.3 2.5 5.0 1.9 virginica
## 148 6.5 3.0 5.2 2.0 virginica
## 149 6.2 3.4 5.4 2.3 virginica
## 150 5.9 3.0 5.1 1.8 virginica
## 151 3.0 3.2 1.6 0.3 newsetosa
dim(iris)
## [1] 151 5
newcol <- 1:151
iris <- cbind(iris , newcol)
name <- c("john" , "peter" , "jennifer" )
gender <- factor (c( "m" , "m" , "f" ))
hw1 <- c(60, 60 ,80)
hw2 <- c( 40 , 50 ,30)
grades <- data.frame(name , gender , hw1 , hw2)
grades
## name gender hw1 hw2
## 1 john m 60 40
## 2 peter m 60 50
## 3 jennifer f 80 30
grades[1 , 2]
## [1] m
## Levels: f m
grades[ , "name"]
## [1] john peter jennifer
## Levels: jennifer john peter
grades$name
## [1] john peter jennifer
## Levels: jennifer john peter
grades[grades$gender=="m",]
## name gender hw1 hw2
## 1 john m 60 40
## 2 peter m 60 50
# subset(dataframe, select=열이름) : 데이터세 트에 서 조건에 맞는 내용을 조회
subset(iris , select=Species, subset=(Petal.Length> 1.7))
## Species
## 25 setosa
## 45 setosa
## 51 versicolor
## 52 versicolor
## 53 versicolor
## 54 versicolor
## 55 versicolor
## 56 versicolor
## 57 versicolor
## 58 versicolor
## 59 versicolor
## 60 versicolor
## 61 versicolor
## 62 versicolor
## 63 versicolor
## 64 versicolor
## 65 versicolor
## 66 versicolor
## 67 versicolor
## 68 versicolor
## 69 versicolor
## 70 versicolor
## 71 versicolor
## 72 versicolor
## 73 versicolor
## 74 versicolor
## 75 versicolor
## 76 versicolor
## 77 versicolor
## 78 versicolor
## 79 versicolor
## 80 versicolor
## 81 versicolor
## 82 versicolor
## 83 versicolor
## 84 versicolor
## 85 versicolor
## 86 versicolor
## 87 versicolor
## 88 versicolor
## 89 versicolor
## 90 versicolor
## 91 versicolor
## 92 versicolor
## 93 versicolor
## 94 versicolor
## 95 versicolor
## 96 versicolor
## 97 versicolor
## 98 versicolor
## 99 versicolor
## 100 versicolor
## 101 virginica
## 102 virginica
## 103 virginica
## 104 virginica
## 105 virginica
## 106 virginica
## 107 virginica
## 108 virginica
## 109 virginica
## 110 virginica
## 111 virginica
## 112 virginica
## 113 virginica
## 114 virginica
## 115 virginica
## 116 virginica
## 117 virginica
## 118 virginica
## 119 virginica
## 120 virginica
## 121 virginica
## 122 virginica
## 123 virginica
## 124 virginica
## 125 virginica
## 126 virginica
## 127 virginica
## 128 virginica
## 129 virginica
## 130 virginica
## 131 virginica
## 132 virginica
## 133 virginica
## 134 virginica
## 135 virginica
## 136 virginica
## 137 virginica
## 138 virginica
## 139 virginica
## 140 virginica
## 141 virginica
## 142 virginica
## 143 virginica
## 144 virginica
## 145 virginica
## 146 virginica
## 147 virginica
## 148 virginica
## 149 virginica
## 150 virginica
subset(iris, select=c(Sepal.Length, Petal.Length, Species), subset=c(Sepal.Width==3.0 & Petal.Width==0.2))
## Sepal.Length Petal.Length Species
## 2 4.9 1.4 setosa
## 26 5.0 1.6 setosa
## 39 4.4 1.3 setosa
#with(dataframe , 열 이름)
head(with(iris , Species))
## [1] setosa setosa setosa setosa setosa setosa
## Levels: setosa versicolor virginica newsetosa
help(with)
#merge(dfl, df2 , by="dfl와 df2의 공통된 열의 이름")
name<-c("TR", "MG", "SH", "PK")
year.born<-c(1995 , 2000, 2009, 2013)
place.born<-c ( "USA" , "KR" , "CHI" , "KR")
born <- data.frame(name, year.born, place.born)
born
## name year.born place.born
## 1 TR 1995 USA
## 2 MG 2000 KR
## 3 SH 2009 CHI
## 4 PK 2013 KR
name<-c("TR" , "MG" , "SH")
year.died<-c(2100 , 2300 , 2500)
died <- data.frame(name, year.died)
died
## name year.died
## 1 TR 2100
## 2 MG 2300
## 3 SH 2500
#데이터프레인 두가지를 이름 항목으로 조합하는 예
merge(born , died , by="name")
## name year.born place.born year.died
## 1 MG 2000 KR 2300
## 2 SH 2009 CHI 2500
## 3 TR 1995 USA 2100
help(merge)
#15 - Sample Source
install.packages("ggplot2")
## Error: trying to use CRAN without setting a mirror
library(ggplot2)
data(movies)
head(movies)
## title year length budget rating votes r1 r2 r3
## 1 $ 1971 121 NA 6.4 348 4.5 4.5 4.5
## 2 $1000 a Touchdown 1939 71 NA 6.0 20 0.0 14.5 4.5
## 3 $21 a Day Once a Month 1941 7 NA 8.2 5 0.0 0.0 0.0
## 4 $40,000 1996 70 NA 8.2 6 14.5 0.0 0.0
## 5 $50,000 Climax Show, The 1975 71 NA 3.4 17 24.5 4.5 0.0
## 6 $pent 2000 91 NA 4.3 45 4.5 4.5 4.5
## r4 r5 r6 r7 r8 r9 r10 mpaa Action Animation Comedy Drama
## 1 4.5 14.5 24.5 24.5 14.5 4.5 4.5 0 0 1 1
## 2 24.5 14.5 14.5 14.5 4.5 4.5 14.5 0 0 1 0
## 3 0.0 0.0 24.5 0.0 44.5 24.5 24.5 0 1 0 0
## 4 0.0 0.0 0.0 0.0 0.0 34.5 45.5 0 0 1 0
## 5 14.5 14.5 4.5 0.0 0.0 0.0 24.5 0 0 0 0
## 6 14.5 14.5 14.5 4.5 4.5 14.5 14.5 0 0 0 1
## Documentary Romance Short
## 1 0 0 0
## 2 0 0 0
## 3 0 0 1
## 4 0 0 0
## 5 0 0 0
## 6 0 0 0
#title 변수에서 skies가 들어간 행 + title , year, rating 변수열 6줄을 조회했다.
#grep(조회할 문자패 턴, data)
head( movies [grep("skies" , movies$title, ignore.case=T) ,c( "title" , "year" , "rating" )] )
## title year rating
## 38 'Neath Canadian Skies 1946 5.4
## 39 'Neath the Arizona Skies 1934 4.6
## 853 Ace Eli and Rodger of the Skies 1973 5.7
## 6512 Blue Montana Skies 1939 5.8
## 6527 Blue Skies 1946 6.3
## 6528 Blue Skies Again 1983 4.9
pattern = "^Summer.*?"
ndx <- grep(pattern , movies$title )
grep(pattern , movies$title )
## [1] 49825 49826 49827 49828 49829 49830 49831 49832 49833 49834 49835
## [12] 49836 49837 49838 49839 49840 49841 49842 49843 49844 49845 49846
## [23] 49847 49848 49849 49850 49851 49852 49853 49854 49855 49856 49857
## [34] 49858 49859 49860 49861 49862 49863 49864 49865 49866 49867 49868
## [45] 49869 49870 49871
head(movies[ndx , "title"])
## [1] "Summer" "Summer Blues" "Summer Camp"
## [4] "Summer Camp Girls" "Summer Camp Nightmare" "Summer Catch"
#벡터에 있는 원소 선택
fib<-c(0 , 1, 1, 2, 3, 5, 8, 13 , 21 , 34)
fib
## [1] 0 1 1 2 3 5 8 13 21 34
fib[1]
## [1] 0
fib[3]
## [1] 1
fib[1:3]
## [1] 0 1 1
fib[c(1 , 2, 4, 8)]
## [1] 0 1 2 13
fib[-1]
## [1] 1 1 2 3 5 8 13 21 34
fib[-c(1:3)]
## [1] 2 3 5 8 13 21 34
fib < 10
## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE
fib[fib<10]
## [1] 0 1 1 2 3 5 8
fib%%2==0
## [1] TRUE FALSE FALSE TRUE FALSE FALSE TRUE FALSE FALSE TRUE
fib[fib%%2==0]
## [1] 0 2 8 34
# as.data. frame(x): 데이터 프레임 형식으로 변환
# as.list(x) 리스트 형식으로 변환.
# as.matrix(x): 행 렬 형 식 으로 변환
# as.vector(x) 벡터 형식으로 변환
# as.factor(x): 팩터 (factor) 형식으로 변환
as.numeric("3.14")
## [1] 3.14
as.integer(3.14)
## [1] 3
as.numeric("Foo")
## Warning: 강제형변환에 의해 생성된 NA 입니다
## [1] NA
# NA or NULLL
as.character(101)
## [1] "101"
as.numeric(FALSE)
## [1] 0
as.numeric(TRUE)
## [1] 1
#문자열을 날짜로 변환
# Sys. Date(): 현재 날짜를 반환
# as.Date(): 날짜 객체로 변환
Sys.Date( )
## [1] "2014-06-02"
as.Date("2013-08-13")
## [1] "2013-08-13"
as.Date("08/13/2013")
## Error: character string is not in a standard unambiguous format
as.Date("08/13/2013", format="%m/%d/%Y")
## [1] "2013-08-13"
#날짜를 문자열로
#format(날짜, 포뱃)
as.Date("08/13/2013", format="%m/%d/%Y")
## [1] "2013-08-13"
format(Sys.Date())
## [1] "2014-06-02"
format(Sys.Date(), format="%m/%d/%Y")
## [1] "06/02/2014"
format(Sys.Date(), '%a')
## [1] "월"
format(Sys.Date(), '%b')
## [1] "6"
format(Sys.Date(), '%B')
## [1] "6월"
format(Sys.Date(), '%d')
## [1] "02"
format(Sys.Date(), '%m')
## [1] "06"
format(Sys.Date(), '%y')
## [1] "14"
format(Sys.Date(), '%Y')
## [1] "2014"
#Missing
a <- 0/0
a
## [1] NaN
is.nan(a)
## [1] TRUE
b <- log(0)
b
## [1] -Inf
is.finite(b)
## [1] FALSE
c <- c(0:4, NA)
is.na(c)
## [1] FALSE FALSE FALSE FALSE FALSE TRUE
# 데이터를 삭제 하는 rm()
rm(a)
rm(list=ls(all=TRUE))
data(iris)
summary(iris)
## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.30 Min. :2.00 Min. :1.00 Min. :0.1
## 1st Qu.:5.10 1st Qu.:2.80 1st Qu.:1.60 1st Qu.:0.3
## Median :5.80 Median :3.00 Median :4.35 Median :1.3
## Mean :5.84 Mean :3.06 Mean :3.76 Mean :1.2
## 3rd Qu.:6.40 3rd Qu.:3.30 3rd Qu.:5.10 3rd Qu.:1.8
## Max. :7.90 Max. :4.40 Max. :6.90 Max. :2.5
## Species
## setosa :50
## versicolor:50
## virginica :50
##
##
##
head(iris)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
head(iris, 10)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5.0 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
#install.packages("party")
#library(party)
# vignette("알고 싶은 package 이 름")
#vignette("party")
#q()
#Data 를 저장하고 읽어들이기
data(iris)
iris <- as.matrix(iris)
head(iris)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## [1,] "5.1" "3.5" "1.4" "0.2" "setosa"
## [2,] "4.9" "3.0" "1.4" "0.2" "setosa"
## [3,] "4.7" "3.2" "1.3" "0.2" "setosa"
## [4,] "4.6" "3.1" "1.5" "0.2" "setosa"
## [5,] "5.0" "3.6" "1.4" "0.2" "setosa"
## [6,] "5.4" "3.9" "1.7" "0.4" "setosa"
dim(iris)
## [1] 150 5
#setwd("D:/SysData/GoogleDrive/빅데이터/Education/SAF_Education/saf_example")
#rm(iris)
#write.csv(iris, file='iris.csv')
#iris <- read.csv("D:/SysData/GoogleDrive/빅데이터/Education/SAF_Education/saf_example/iris.csv")
#summary(iris)
#iris <- as.data.frame(iris)
#str(iris)
#a <- iris$Species
#save(a,file="exercise.Rdata")