Installing MySQL 5
To install MySQL, we do this:
[root@~]# yum -y install mysql mysql-server
Then we create the system startup links for MySQL (so that MySQL starts automatically whenever the system boots) and start the MySQL server:
chkconfig --levels 235 mysqld on
[root@~]# /etc/init.d/mysqld start
Set passwords for the MySQL root account:
mysql_secure_installation
[root@~]# mysql_secure_installation
Installing Apache2
Apache2 is available as a CentOS package, therefore we can install it like this:
[root@~]# yum -y install httpd
Now configure your system to start Apache at boot time...
chkconfig --levels 235 httpd on
... and start Apache:
[root@~]# /etc/init.d/httpd start
Now direct your browser to http://192.168.0.100, and you should see the Apache2 placeholder page:
Apache's default document root is /var/www/html on CentOS, and the configuration file is /etc/httpd/conf/httpd.conf. Additional configurations are stored in the /etc/httpd/conf.d/ directory.
[root@~]# vi /etc/sysconfig/iptables
cofig files input
......
-A INPUT -m state --state NEW -m tcp -p tcp --dport 80 -j ACCEPT
[root@~]# service iptables restart
Installing PHP5
We can install PHP5 and the Apache PHP5 module as follows:
[root@~]# yum -y install php
We must restart Apache afterwards:
[root@~]# /etc/init.d/httpd restart
5 Testing PHP5 / Getting Details About Your PHP5 Installation
The document root of the default web site is /var/www/html. We will now create a small PHP file (info.php) in that directory and call it in a browser. The file will display lots of useful details about our PHP installation, such as the installed PHP version.
[root@~]# vi /var/www/html/info.php
<?php
phpinfo();
?>
Now we call that file in a browser (e.g. http://192.168.0.100/info.php):
As you see, PHP5 is working, and it's working through the Apache 2.0 Handler, as shown in the Server API line. If you scroll further down, you will see all modules that are already enabled in PHP5. MySQL is not listed there which means we don't have MySQL support in PHP5 yet.
6 Getting MySQL Support In PHP5
To get MySQL support in PHP, we can install the php-mysql package. It's a good idea to install some other PHP5 modules as well as you might need them for your applications. You can search for available PHP5 modules like this:
[root@~]# yum search php
Pick the ones you need and install them like this:
[root@~]# yum -y install php-mysql
In the next step I will install some common PHP modules that are required by CMS Systems like Wordpress, Joomla and Drupal:
[root@~]# yum -y install php-gd php-imap php-ldap php-odbc php-pear php-xml php-xmlrpc php-mbstring php-mcrypt php-mssql php-snmp php-soap php-tidy curl curl-devel
APC is a free and open PHP opcode cacher for caching and optimizing PHP intermediate code. It's similar to other PHP opcode cachers, such as eAccelerator and Xcache. It is strongly recommended to have one of these installed to speed up your PHP page.
APC can be installed as follows:
[root@~]# yum -y install php-pecl-apc
Now restart Apache2:
[root@~]# /etc/init.d/httpd restart
Now reload http://localhost/info.php in your browser and scroll down to the modules section again. You should now find lots of new modules there, including the APC module:
phpMyAdmin
phpMyAdmin is a web interface through which you can manage your MySQL databases.
First we enable the RPMforge repository on our CentOS system as phpMyAdmin is not available in the official CentOS 6.5 repositories:
Import the RPMforge GPG key:
[root@~]# rpm --import http://dag.wieers.com/rpm/packages/RPM-GPG-KEY.dag.txt
On x86_64 systems:
[root@~]# yum -y install http://pkgs.repoforge.org/rpmforge-release/rpmforge-release-0.5.3-1.el6.rf.x86_64.rpm
On i386 systems:
[root@~]# yum -y install http://pkgs.repoforge.org/rpmforge-release/rpmforge-release-0.5.3-1.el6.rf.i686.rpm
phpMyAdmin can now be installed as follows:
[root@~]# yum -y install phpmyadmin
Now we configure phpMyAdmin. We change the Apache configuration so that phpMyAdmin allows connections not just from localhost (by commenting out the <Directory "/usr/share/phpmyadmin"> stanza):
[root@~]# vi /etc/httpd/conf.d/phpmyadmin.conf
#
# Web application to manage MySQL
#
#<Directory "/usr/share/phpmyadmin">
# Order Deny,Allow
# Deny from all
# Allow from 127.0.0.1
#</Directory>
Alias /phpmyadmin /usr/share/phpmyadmin
Alias /phpMyAdmin /usr/share/phpmyadmin
Alias /mysqladmin /usr/share/phpmyadmin
Next we change the authentication in phpMyAdmin from cookie to http:
[root@~]# vi /usr/share/phpmyadmin/config.inc.php
[...]
/* Authentication type */
$cfg['Servers'][$i]['auth_type'] = 'http';
or
$cfg['Servers'][$i]['auth_type'] = 'cookie';
[...]
Restart Apache:
[root@~]# /etc/init.d/httpd restart
Afterwards, you can access phpMyAdmin under http://localhost/phpmyadmin/:
2014년 8월 7일 목요일
[CentOS] SSH Config - PermitRootLogin
## CentOS 6.5 64Bit Version
OpenSSH Configuration Files
[root@dev]# vi /etc/ssh/sshd_config
[root@dev]# /etc/rc.d/init.d/sshd restart
# LoginGraceTime 2m
설정한 시간내에 로그인 하지 않으면 자동으로 접속을 끊도록 설정 한다. 값을 0으로 하면 무제한 이다.
# PermitRootLogin no
기본값은 주석처리 되어 있어 기본으로 값은 'yes' 이다. 공격자가 임의의 주소에 root 계정으로 접속이 가능한지 여부를 알아 낼 수 있다. 따라서 위와 같이 root 계정의 접근을 막고 일반 유저로 접속한 다음 root 계정으로 전환 하는 것이 일반적이다.
# MaxAuthTries 6
접속당 최대 인증 시도 횟수. 기본값 6, 3회이상 인증 실패시 로그가 기록
2014년 8월 6일 수요일
[ITS 일반] Mail Server Error Return Message Type
■ 원인
- 받는 메일 서비스에 장애가 생겼을 때
- 받는 사람의 메일 주소가 정확하지 않았을때
- 수신자의 메일함 용량이 초돠되어 더 이상 메일을 받을 수 없을 때
- 받는 사람이 수신거부를 설정하였을때
CONNECTION ERROR:
421 4.4.1 IP ADDRESS: Network is busy.
한메일 수신 서버가 응답을 못하는 상황입니다. 잠시 후 다시 접속을 시도해 주시기 바랍니다.
421 4.4.5 IP ADDRESS: Connection refused. Server is busy.
한메일 수신서버에 동시접속 가능한 수를 초과하였습니다. (white IP기준 100개)
접속 수를 줄여 재발송을 시도해 주시기 바랍니다.
554 5.7.1 IP ADDRESS: Connection refused. Your IP address is blocked.
Daum 스팸센터에서 해당IP를 스팸IP로 판단하여 접속을 차단하였습니다.
자세한 사항은 스팸센터로 문의 하시기 바랍니다.
COMMAND ERROR:
421 4.4.0 IP ADDRESS: Closing connection by timeout
시간초과로 한메일 수신 서버 접속이 끊겼습니다. 다시 접속해 주시기 바랍니다.
421 4.7.0 IP ADDRESS: Too many bad commands
사용 불가능한 명령어의 제한 수를 초과하였습니다. 명령어를 확인 후 다시 입력하시기 바랍니다.
421 4.7.0 IP ADDRESS: Too many transactions
한 번 접속 후 접속을 끊지 않고 계속해서 메일을 발송할 경우, 일정양의 메일 수신후 한메일 서버에서 더 이상의 메일수신을 거부합니다. 메일 발송 시, 기존 접속을 끊고 새로운 접속을 맺으셔야 합니다.
500 5.5.0 IP ADDRESS: Command line too long
명령어가 제한길이인 8,192 바이트를 초과하였습니다. 명령어를 확인 후 다시 입력하시기 바랍니다.
500 5.5.2 IP ADDRESS: Command not recognized: UNRECOGNIZED COMMAND
한메일 수신 서버가 이해할 수 없는 명령어 입니다. SMTP 규약에 맞게 수정 후 다시 입력해 주시기 바랍니다.
501 5.5.2 IP ADDRESS: Syntax error in command line: COMMAND LINE
명령어 구문에 오류가 있습니다. SMTP 규약에 맞게 수정 후 다시 입력해 주시기 바랍니다.
501 5.5.4 IP ADDRESS: EHLO requires domain name
EHLO 명령어에 도메인 명이 포함되어 있지 않아 반송되었습니다. 도메인 명을 포함한 명령어를 다시 입력해 주시기 바랍니다.
501 5.5.4 IP ADDRESS: Command argument required
명령어에 필요한 인자값이 없습니다. SMTP 규약에 맞게 수정 후 다시 입력해 주시기 바랍니다.
501 5.5.4 IP ADDRESS: Invalid command argument: ARGUMENT
명령어 중 인자의 포맷이 올바르지 않습니다. SMTP 규약에 수정 다시 입력해 주시기 바랍니다.
502 5.5.1 IP ADDRESS: Command not implemented: UNIMPLEMENTED COMMAND
이 메시지로는 정확한 에러 사항을 파악할 수 없습니다.
telnet으로 한메일 수신 서버에 접속하여 발송하기까지의 로그를 복사하여 보내주시면 문제를 확인해 드리겠습니다.
한메일 수신 서버 아이피 : 222.231.35.29
MAIL COMMAND ERROR:
450 4.7.1 IP ADDRESS: Message refused. Your IP address has sent too many mails(MAIL COUNT).
한메일로 전송 가능한 메일 통수를 초과하였습니다. 자세한 사항은 스팸센터로 문의해 주시기 바랍니다.
451 4.4.1 IP ADDRESS: Network is busy(TYPE)
보낸이의 메일주소가 유효한 Daum 사용자인지 확인하던 중, 일시적인 오류가 발생하였습니다. 잠시 후 재전송을 시도해 주십시오.
503 5.5.1 IP ADDRESS: Sender already specified
보낸이의 메일 주소가 이미 정의되어 있습니다. SMTP 규약에 따라 보낸이의 메일주소는 중복해서 정의될 수 없습니다.
명령어를 확인하신 후 다시 발송시도 해주시기 바랍니다.
550 5.1.8 IP ADDRESS: No such user: SENDER ADDRESS
보낸이의 메일 주소가 Daum에 가입되지 않은 아이디입니다. 보낸이 주소를 확인 후, 재 발송해 주시기 바랍니다.
553 5.1.7 IP ADDRESS: Invalid mail address: SENDER ADDRESS
보낸이의 메일 주소가 한메일 수신 서버에서 확인되지 않는 주소입니다. 보낸이 주소를 확인 후, 재발송 해주시기 바랍니다.
RCPT COMMAND ERROR:
450 4.5.3 IP ADDRESS: Too many recipients
한메일 수신서버가 한번에 받을수 있는 받는이 수 제한을 초과했습니다. 받는이를 나눠서 메일을 재발송해주십시오.
451 4.2.0 IP ADDRESS: Temporary home error: RECIPIENT ADDRESS
받는이의 한메일 홈서버에 일시적인 장애가 있어서 메일을 수신할 수가 없습니다. 잠시 후 다시 시도해 주시기 바랍니다.
451 4.4.1 IP ADDRESS: Network is busy
받는이의 메일주소가 유효한 Daum 사용자인지 확인하던 중, 일시적인 오류가 발생하였습니다. 잠시 후 재전송을 시도해 주십시오.
503 5.5.1 IP ADDRESS: MAIL command required
받는이의 메일주소를 정의하기 전에 반드시 보낸이의 메일주소를 정의하여야 합니다.
SMTP 규약에 맞게 명령어를 다시 입력해주시기 바랍니다.
550 5.1.1 IP ADDRESS: No such user: RECIPIENT ADDRESS
받는이의 메일주소가 Daum에 가입되지 않은 아이디입니다. 받는이 주소를 확인 후 다시 발송해 주시기 바랍니다.
550 5.2.0 IP ADDRESS: Message refused by the recipient: RECIPIENT ADDRESS
받는이가 보낸이 주소를 ‘수신거부’ 혹은 ‘바로삭제’로 설정하여 메일이 전달될 수 없습니다.
550 5.2.1 IP ADDRESS: Mailbox is inactive: RECIPIENT ADDRESS
받는이가 Daum에 로그인한지 3개월 이상 지나 휴면계정으로 전환된 사용자입니다.
Daum 휴면 사용자는 메일을 수신할 수 없습니다.
552 5.2.2 IP ADDRESS: Mailbox is full: RECIPIENT ADDRESS
받는이의 편지함이 가득 차서 더 이상 메일을 수신할 수 없습니다.
받는이에게 다른 방법으로 연락이 가능하시다면 한메일의 편지함 정리를 요청해주시기 바랍니다.
553 5.1.2 IP ADDRESS: Relaying denied: RECIPIENT ADDRESS
@hanmail.net 또는 @daum.net이 아닌 주소로 메일을 발송하였습니다. 받는이 메일 주소를 확인 후, 다시 발송해 주시기 바랍니다.
553 5.1.3 IP ADDRESS: Invalid mail address: RECIPIENT ADDRESS
받는이의 메일 주소가 정확하지 않습니다. 확인후 재발송 해주시기 바랍니다.
DATA COMMAND ERROR:
451 4.4.1 IP ADDRESS: MESSAGE ID Network is busy
한메일 수신서버 네트워크의 일시적인 오류로 인하여 메일이 전달되지 않거나, 저장이 되지 않았습니다.
잠시 후, 발송을 다시 시도해 주시기 바랍니다.
503 5.5.1 IP ADDRESS: MAIL command required
보낸이의 메일주소가 정의되지 않았습니다. 확인 후 다시 명령어를 입력해 주시기 바랍니다.
503 5.5.1 IP ADDRESS: RCPT command required(recipient)
받는이의 메일주소가 정의되지 않았습니다. 1명 이상의 받는이 주소를 포함시켜 다시 발송해 주시기 바랍니다.
552 5.2.3 IP ADDRESS: Message size exceeds the limit(LIMIT)
메일이 수신 제한 용량을 초과하였습니다. (일반 회원:20M, 프리미엄 회원:50M)
사이즈를 줄여 다시 발송해 주시기 바랍니다.
554 5.4.6 IP ADDRESS: Routing loop detected
한메일 수신 서버가 이미 해당 메일을 수신하였습니다. 발송 서버의 루핑이 예상되오니, 확인을 부탁드립니다.
554 5.6.0 IP ADDRESS: Message requires 'From' header
헤더에 보낸이 정보가 없는 경우 수신을 거부합니다. 정확한 보낸이 주소를 포함하여 다시 발송해주시기 바랍니다.
554 5.6.0 IP ADDRESS: Invalid 'From' header: FROM
헤더의 보낸이 정보가 ‘RFC2822 인터넷 메시지 규정’에 맞지 않는 경우 수신을 거부합니다.
RFC 규정을 참고 후, 다시 발송해주시기 바랍니다.
554 5.7.1 IP ADDRESS: Message refused. Your host name(HOST NAME) dosen't match with your IP address.
메일발송 IP 정보와 Hostname 정보가 일치하지 않아 해당 메일 수신을 거부합니다.
발송 서버에 ‘MX레코드’와 ‘리버스 도메인’이 등록되어 있는지 확인해주시기 바랍니다. 2개 모두 정확히 등록되어 있어야 합니다.
도메인 설정이 정확한지 네트워크 담당자에게 문의해주세요.
554 5.7.1 IP ADDRESS: Message refused. Your domain(DOMAIN) has sent too many mails.
해당 도메인에서 너무 많은 메일이 발송되어, 한메일 수신이 원활하지 않습니다. 잠시 후 다시 발송해 주시기 바랍니다.
554 5.7.7 IP ADDRESS: Message not terminated by end with "." on a line by itself
DATA 명령어가 끝나기 전에 클라이언트가 닫혔기 때문에 해당 메일을 전달할수 없습니다.
SMTP 규약에 따라 “.” 명령어를 포함하여 다시 입력해 주시기 바랍니다.
- 받는 메일 서비스에 장애가 생겼을 때
- 받는 사람의 메일 주소가 정확하지 않았을때
- 수신자의 메일함 용량이 초돠되어 더 이상 메일을 받을 수 없을 때
- 받는 사람이 수신거부를 설정하였을때
CONNECTION ERROR:
421 4.4.1 IP ADDRESS: Network is busy.
한메일 수신 서버가 응답을 못하는 상황입니다. 잠시 후 다시 접속을 시도해 주시기 바랍니다.
421 4.4.5 IP ADDRESS: Connection refused. Server is busy.
한메일 수신서버에 동시접속 가능한 수를 초과하였습니다. (white IP기준 100개)
접속 수를 줄여 재발송을 시도해 주시기 바랍니다.
554 5.7.1 IP ADDRESS: Connection refused. Your IP address is blocked.
Daum 스팸센터에서 해당IP를 스팸IP로 판단하여 접속을 차단하였습니다.
자세한 사항은 스팸센터로 문의 하시기 바랍니다.
COMMAND ERROR:
421 4.4.0 IP ADDRESS: Closing connection by timeout
시간초과로 한메일 수신 서버 접속이 끊겼습니다. 다시 접속해 주시기 바랍니다.
421 4.7.0 IP ADDRESS: Too many bad commands
사용 불가능한 명령어의 제한 수를 초과하였습니다. 명령어를 확인 후 다시 입력하시기 바랍니다.
421 4.7.0 IP ADDRESS: Too many transactions
한 번 접속 후 접속을 끊지 않고 계속해서 메일을 발송할 경우, 일정양의 메일 수신후 한메일 서버에서 더 이상의 메일수신을 거부합니다. 메일 발송 시, 기존 접속을 끊고 새로운 접속을 맺으셔야 합니다.
500 5.5.0 IP ADDRESS: Command line too long
명령어가 제한길이인 8,192 바이트를 초과하였습니다. 명령어를 확인 후 다시 입력하시기 바랍니다.
500 5.5.2 IP ADDRESS: Command not recognized: UNRECOGNIZED COMMAND
한메일 수신 서버가 이해할 수 없는 명령어 입니다. SMTP 규약에 맞게 수정 후 다시 입력해 주시기 바랍니다.
501 5.5.2 IP ADDRESS: Syntax error in command line: COMMAND LINE
명령어 구문에 오류가 있습니다. SMTP 규약에 맞게 수정 후 다시 입력해 주시기 바랍니다.
501 5.5.4 IP ADDRESS: EHLO requires domain name
EHLO 명령어에 도메인 명이 포함되어 있지 않아 반송되었습니다. 도메인 명을 포함한 명령어를 다시 입력해 주시기 바랍니다.
501 5.5.4 IP ADDRESS: Command argument required
명령어에 필요한 인자값이 없습니다. SMTP 규약에 맞게 수정 후 다시 입력해 주시기 바랍니다.
501 5.5.4 IP ADDRESS: Invalid command argument: ARGUMENT
명령어 중 인자의 포맷이 올바르지 않습니다. SMTP 규약에 수정 다시 입력해 주시기 바랍니다.
502 5.5.1 IP ADDRESS: Command not implemented: UNIMPLEMENTED COMMAND
이 메시지로는 정확한 에러 사항을 파악할 수 없습니다.
telnet으로 한메일 수신 서버에 접속하여 발송하기까지의 로그를 복사하여 보내주시면 문제를 확인해 드리겠습니다.
한메일 수신 서버 아이피 : 222.231.35.29
MAIL COMMAND ERROR:
450 4.7.1 IP ADDRESS: Message refused. Your IP address has sent too many mails(MAIL COUNT).
한메일로 전송 가능한 메일 통수를 초과하였습니다. 자세한 사항은 스팸센터로 문의해 주시기 바랍니다.
451 4.4.1 IP ADDRESS: Network is busy(TYPE)
보낸이의 메일주소가 유효한 Daum 사용자인지 확인하던 중, 일시적인 오류가 발생하였습니다. 잠시 후 재전송을 시도해 주십시오.
503 5.5.1 IP ADDRESS: Sender already specified
보낸이의 메일 주소가 이미 정의되어 있습니다. SMTP 규약에 따라 보낸이의 메일주소는 중복해서 정의될 수 없습니다.
명령어를 확인하신 후 다시 발송시도 해주시기 바랍니다.
550 5.1.8 IP ADDRESS: No such user: SENDER ADDRESS
보낸이의 메일 주소가 Daum에 가입되지 않은 아이디입니다. 보낸이 주소를 확인 후, 재 발송해 주시기 바랍니다.
553 5.1.7 IP ADDRESS: Invalid mail address: SENDER ADDRESS
보낸이의 메일 주소가 한메일 수신 서버에서 확인되지 않는 주소입니다. 보낸이 주소를 확인 후, 재발송 해주시기 바랍니다.
RCPT COMMAND ERROR:
450 4.5.3 IP ADDRESS: Too many recipients
한메일 수신서버가 한번에 받을수 있는 받는이 수 제한을 초과했습니다. 받는이를 나눠서 메일을 재발송해주십시오.
451 4.2.0 IP ADDRESS: Temporary home error: RECIPIENT ADDRESS
받는이의 한메일 홈서버에 일시적인 장애가 있어서 메일을 수신할 수가 없습니다. 잠시 후 다시 시도해 주시기 바랍니다.
451 4.4.1 IP ADDRESS: Network is busy
받는이의 메일주소가 유효한 Daum 사용자인지 확인하던 중, 일시적인 오류가 발생하였습니다. 잠시 후 재전송을 시도해 주십시오.
503 5.5.1 IP ADDRESS: MAIL command required
받는이의 메일주소를 정의하기 전에 반드시 보낸이의 메일주소를 정의하여야 합니다.
SMTP 규약에 맞게 명령어를 다시 입력해주시기 바랍니다.
550 5.1.1 IP ADDRESS: No such user: RECIPIENT ADDRESS
받는이의 메일주소가 Daum에 가입되지 않은 아이디입니다. 받는이 주소를 확인 후 다시 발송해 주시기 바랍니다.
550 5.2.0 IP ADDRESS: Message refused by the recipient: RECIPIENT ADDRESS
받는이가 보낸이 주소를 ‘수신거부’ 혹은 ‘바로삭제’로 설정하여 메일이 전달될 수 없습니다.
550 5.2.1 IP ADDRESS: Mailbox is inactive: RECIPIENT ADDRESS
받는이가 Daum에 로그인한지 3개월 이상 지나 휴면계정으로 전환된 사용자입니다.
Daum 휴면 사용자는 메일을 수신할 수 없습니다.
552 5.2.2 IP ADDRESS: Mailbox is full: RECIPIENT ADDRESS
받는이의 편지함이 가득 차서 더 이상 메일을 수신할 수 없습니다.
받는이에게 다른 방법으로 연락이 가능하시다면 한메일의 편지함 정리를 요청해주시기 바랍니다.
553 5.1.2 IP ADDRESS: Relaying denied: RECIPIENT ADDRESS
@hanmail.net 또는 @daum.net이 아닌 주소로 메일을 발송하였습니다. 받는이 메일 주소를 확인 후, 다시 발송해 주시기 바랍니다.
553 5.1.3 IP ADDRESS: Invalid mail address: RECIPIENT ADDRESS
받는이의 메일 주소가 정확하지 않습니다. 확인후 재발송 해주시기 바랍니다.
DATA COMMAND ERROR:
451 4.4.1 IP ADDRESS: MESSAGE ID Network is busy
한메일 수신서버 네트워크의 일시적인 오류로 인하여 메일이 전달되지 않거나, 저장이 되지 않았습니다.
잠시 후, 발송을 다시 시도해 주시기 바랍니다.
503 5.5.1 IP ADDRESS: MAIL command required
보낸이의 메일주소가 정의되지 않았습니다. 확인 후 다시 명령어를 입력해 주시기 바랍니다.
503 5.5.1 IP ADDRESS: RCPT command required(recipient)
받는이의 메일주소가 정의되지 않았습니다. 1명 이상의 받는이 주소를 포함시켜 다시 발송해 주시기 바랍니다.
552 5.2.3 IP ADDRESS: Message size exceeds the limit(LIMIT)
메일이 수신 제한 용량을 초과하였습니다. (일반 회원:20M, 프리미엄 회원:50M)
사이즈를 줄여 다시 발송해 주시기 바랍니다.
554 5.4.6 IP ADDRESS: Routing loop detected
한메일 수신 서버가 이미 해당 메일을 수신하였습니다. 발송 서버의 루핑이 예상되오니, 확인을 부탁드립니다.
554 5.6.0 IP ADDRESS: Message requires 'From' header
헤더에 보낸이 정보가 없는 경우 수신을 거부합니다. 정확한 보낸이 주소를 포함하여 다시 발송해주시기 바랍니다.
554 5.6.0 IP ADDRESS: Invalid 'From' header: FROM
헤더의 보낸이 정보가 ‘RFC2822 인터넷 메시지 규정’에 맞지 않는 경우 수신을 거부합니다.
RFC 규정을 참고 후, 다시 발송해주시기 바랍니다.
554 5.7.1 IP ADDRESS: Message refused. Your host name(HOST NAME) dosen't match with your IP address.
메일발송 IP 정보와 Hostname 정보가 일치하지 않아 해당 메일 수신을 거부합니다.
발송 서버에 ‘MX레코드’와 ‘리버스 도메인’이 등록되어 있는지 확인해주시기 바랍니다. 2개 모두 정확히 등록되어 있어야 합니다.
도메인 설정이 정확한지 네트워크 담당자에게 문의해주세요.
554 5.7.1 IP ADDRESS: Message refused. Your domain(DOMAIN) has sent too many mails.
해당 도메인에서 너무 많은 메일이 발송되어, 한메일 수신이 원활하지 않습니다. 잠시 후 다시 발송해 주시기 바랍니다.
554 5.7.7 IP ADDRESS: Message not terminated by end with "." on a line by itself
DATA 명령어가 끝나기 전에 클라이언트가 닫혔기 때문에 해당 메일을 전달할수 없습니다.
SMTP 규약에 따라 “.” 명령어를 포함하여 다시 입력해 주시기 바랍니다.
2014년 7월 28일 월요일
[MSSQL] Windows 7 - ODBC "SQLSTATE = IM014" Error Tip
[Error Messages] SQLSTATE = IM014
Source URL - http://msdn.microsoft.com/en-us/library/windows/desktop/ms712362%28v=vs.85%29.aspx
To manage a data source that connects to a 32-bit driver under 64-bit platform, use c:\windows\sysWOW64\odbcad32.exe. To manage a data source that connects to a 64-bit driver, use c:\windows\system32\odbcad32.exe. In Administrative Tools on a 64-bit Windows 8 operating system, there are icons for both the 32-bit and 64-bit ODBC Data Source Administrator dialog box.
2014년 6월 12일 목요일
[SAF 데이터분석과정 참고] # 통계기초 - 모집단(Population), 표본집단(Sample)
모집단(Population) 이란 어떤 정보를 얻고자 하는 전체 대상 또는 전체 집합을 의미 한다. 그러나 이에 반에 표본집단(Sample)은 모집단으로 부터 추출된 모지받느이 부분 집합으로 이해할 수 있다.
예를들어 2회 이상 방문하신 남성고객과 여성고객의 평균매출금액을 비교한다고 할때 여기서 모집단은 2회이상 방문한 남성고객의 평균매출과 2회이상 방문한 여성고객의 평균매출이 된다. 모든 데이터를 확인하여 얼마나 차이가 있는지 두개의 집단을 비교 분석 할 수 있을지 모른다. 전수조사를 하는것보다 전체 모집단에서 일부분을 추출하여(표본집단) 그 차이를 비교하면 알수 있다. 하지만 전수조사와 같이 100% 정확하다고 말할 순 없다. 표본 집단은 이렇게 모집단을 대표할 수 있는 부분집합이라고 할 수 있는데 비록 정확도가 떨어지긴 하지만 설계하는 방법에 따라 표준집단을 통해 모집단의 특성을 99% 혹은 그 이상의 신뢰도를 가지고 추정할 수 있다.
통계학은 이렇게 실질적, 경제적 또는 그 외 다른 이유로 그 값을 모두 측절할 수 없는 모 집단이 있다고 할 때, 허용될 수 있는 오차 또는 신뢰도를 만족할 수 있는 최소한의 표본을 추출한 후 표본 집단에서 관측 또는 측적된 값으로 모집단의 특성을 추정하는 방법 이라고 할 수 있다. 모집단의 특성을 나타내는 중요한 수치로 평균, 중앙값, 표준편차등의 값이 있다.
표본집단을 추출할 때에는 아래와 같은 사항을 반드시 고려
1) 추출할 표본집단의 크기 ( Sample Size )
2) 표본 추출 방법 ( Sampling Method )
일반적으로 표본을 추출할때는 무작위 표본 추출(Random Sampling)을 사용한다. 서로 관련성이 없는 표본만을 추출하는 것을 의미 함.
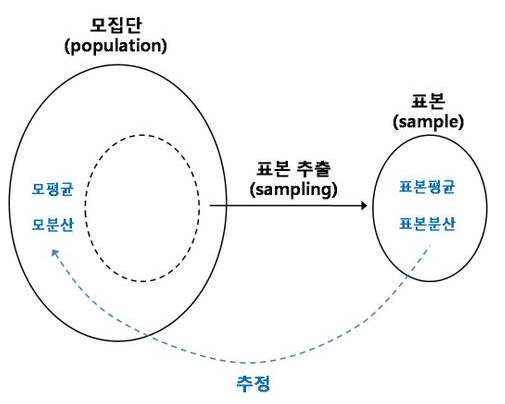
* 사전적의미
모집단(population) : 통계적인 관찰의 대상이 되는 집단 전체
표본(Sample) : 전체 모집단의 축도 또는 단면이 된다는 가정하에서 모집단에서 선택된 모집단 구성단위이 일부
예를들어 2회 이상 방문하신 남성고객과 여성고객의 평균매출금액을 비교한다고 할때 여기서 모집단은 2회이상 방문한 남성고객의 평균매출과 2회이상 방문한 여성고객의 평균매출이 된다. 모든 데이터를 확인하여 얼마나 차이가 있는지 두개의 집단을 비교 분석 할 수 있을지 모른다. 전수조사를 하는것보다 전체 모집단에서 일부분을 추출하여(표본집단) 그 차이를 비교하면 알수 있다. 하지만 전수조사와 같이 100% 정확하다고 말할 순 없다. 표본 집단은 이렇게 모집단을 대표할 수 있는 부분집합이라고 할 수 있는데 비록 정확도가 떨어지긴 하지만 설계하는 방법에 따라 표준집단을 통해 모집단의 특성을 99% 혹은 그 이상의 신뢰도를 가지고 추정할 수 있다.
통계학은 이렇게 실질적, 경제적 또는 그 외 다른 이유로 그 값을 모두 측절할 수 없는 모 집단이 있다고 할 때, 허용될 수 있는 오차 또는 신뢰도를 만족할 수 있는 최소한의 표본을 추출한 후 표본 집단에서 관측 또는 측적된 값으로 모집단의 특성을 추정하는 방법 이라고 할 수 있다. 모집단의 특성을 나타내는 중요한 수치로 평균, 중앙값, 표준편차등의 값이 있다.
표본집단을 추출할 때에는 아래와 같은 사항을 반드시 고려
1) 추출할 표본집단의 크기 ( Sample Size )
2) 표본 추출 방법 ( Sampling Method )
일반적으로 표본을 추출할때는 무작위 표본 추출(Random Sampling)을 사용한다. 서로 관련성이 없는 표본만을 추출하는 것을 의미 함.
[이미지출철-췌인양의블러그]
* 사전적의미
모집단(population) : 통계적인 관찰의 대상이 되는 집단 전체
표본(Sample) : 전체 모집단의 축도 또는 단면이 된다는 가정하에서 모집단에서 선택된 모집단 구성단위이 일부
2014년 6월 10일 화요일
[SAF 데이터분석과정 참고] # 통계기초 - 척도(Scale)
# 아래 내용은 SAF(SUNATFOOD) 데이터분석과정 중 통계학 관련 정보 중 기초적으로 이해하고자 하는 부분을 간략하게 정리하기 위해서 만든 자료임.
# 참고된 자료는 하단의 참고링크 및 내역에 공유한다.
관측되거나 측정, 수집된 자료는 서로 다른 것들과는 구분되는 특성을 가지게 되는데, 척도(Scale)는 이러한 자료의 특성을 정의하는 구분자로 말할 수 있다. 통계학에서 사용하는 척도로는 명목, 순위, 간격, 비 척도의 네가지로 구분된다.
* 범주형 자료(Categorical Data) = 질적자료(Qualiative Data)
* 연속형 자료(Numerical Data) = 양적자료(Quantitative Data)
1. 명목척도(nominal scale)
설명(남,여), 객층구분(성인, 어린이, 외국인), 직군구분(홀-FOH, 주방-BOH) 등 자료를 구성하는 값들이 특정 상태를 지정할 경우 명목 척도 자료라고 한다. 범주형(Category) 자료이기 때문에 사칙연산이나 수학적인 함수 사용에 대한 조작이 불가능 하다.
2. 순위척도(ordinal scale)
매출순위(1위~30위), 쿠폰반응(좋음, 보통, 나쁨) 등과 같이 자료를 구성하는 특성 상태와 순위정보도 가지고 있는 경우를 말한다. 명목 척도와 같이 범주형자료 임. 그러나 1위, 2위 처럼 순위를 구분하기 위한 숫자가 쓰여 있긴 하지만 숫자에 대한 의미보다는 구분을 위한 표현이라고 할 수 있다. 명목척도와 같이 순위 척도는 사칙연산에 활용할 수 없지만 특성의 값을 무시하거나 좋음, 보통, 나쁨을 숫자형 자료로 환산하여 1, 0, -1 등으로 활용한다면 활용은 가능하다.
3. 간격척도(interval scale)
거리척도라고도 한다. 특정한 상태의 지칭이나 대소관계 개념 외에도 측정치간의 간격에 의미를 부여할 수 있을 때 이러한 변수를 간격척도라고 한다. 온도의 경우 20도와 30도의 차이가 10도인것과 같이 90도와 100도의 차이가 10도는 동일하다고 할 수 있다. 수학적인 덧샘과 뺄샘은 가능하나 곱셈과 나눗셈은 불가능하다는 특징을 가지고 있다. 위의 명목, 순위척도와 달리 연속형 자료이다. 평균, 중앙값 등과 같은 기술 통계량을 계산할 수 있다.
4. 비율 척도(ratio scale)
절대 영점을 가지고 있으며, 자연계에서 관측되거나 측정되는 거의 모든 수치가 비 척도로 표시 된다. 예를들어 체지방량이 20인 사람과 40인사람의 경우 20만큼의 체지방량의 차이가 있다고 할수 있다. 또한 체지방량이 2배라고도 할 수 있다. 일상생활에서 자주 보는 연속형 자료에 해당이 된다. 또한 자료 변환을 통하여 명목척도나 간격척도로도 활용이 가능하다.
# 참고된 자료는 하단의 참고링크 및 내역에 공유한다.
관측되거나 측정, 수집된 자료는 서로 다른 것들과는 구분되는 특성을 가지게 되는데, 척도(Scale)는 이러한 자료의 특성을 정의하는 구분자로 말할 수 있다. 통계학에서 사용하는 척도로는 명목, 순위, 간격, 비 척도의 네가지로 구분된다.
* 범주형 자료(Categorical Data) = 질적자료(Qualiative Data)
* 연속형 자료(Numerical Data) = 양적자료(Quantitative Data)
1. 명목척도(nominal scale)
설명(남,여), 객층구분(성인, 어린이, 외국인), 직군구분(홀-FOH, 주방-BOH) 등 자료를 구성하는 값들이 특정 상태를 지정할 경우 명목 척도 자료라고 한다. 범주형(Category) 자료이기 때문에 사칙연산이나 수학적인 함수 사용에 대한 조작이 불가능 하다.
2. 순위척도(ordinal scale)
매출순위(1위~30위), 쿠폰반응(좋음, 보통, 나쁨) 등과 같이 자료를 구성하는 특성 상태와 순위정보도 가지고 있는 경우를 말한다. 명목 척도와 같이 범주형자료 임. 그러나 1위, 2위 처럼 순위를 구분하기 위한 숫자가 쓰여 있긴 하지만 숫자에 대한 의미보다는 구분을 위한 표현이라고 할 수 있다. 명목척도와 같이 순위 척도는 사칙연산에 활용할 수 없지만 특성의 값을 무시하거나 좋음, 보통, 나쁨을 숫자형 자료로 환산하여 1, 0, -1 등으로 활용한다면 활용은 가능하다.
3. 간격척도(interval scale)
거리척도라고도 한다. 특정한 상태의 지칭이나 대소관계 개념 외에도 측정치간의 간격에 의미를 부여할 수 있을 때 이러한 변수를 간격척도라고 한다. 온도의 경우 20도와 30도의 차이가 10도인것과 같이 90도와 100도의 차이가 10도는 동일하다고 할 수 있다. 수학적인 덧샘과 뺄샘은 가능하나 곱셈과 나눗셈은 불가능하다는 특징을 가지고 있다. 위의 명목, 순위척도와 달리 연속형 자료이다. 평균, 중앙값 등과 같은 기술 통계량을 계산할 수 있다.
4. 비율 척도(ratio scale)
절대 영점을 가지고 있으며, 자연계에서 관측되거나 측정되는 거의 모든 수치가 비 척도로 표시 된다. 예를들어 체지방량이 20인 사람과 40인사람의 경우 20만큼의 체지방량의 차이가 있다고 할수 있다. 또한 체지방량이 2배라고도 할 수 있다. 일상생활에서 자주 보는 연속형 자료에 해당이 된다. 또한 자료 변환을 통하여 명목척도나 간격척도로도 활용이 가능하다.
2014년 6월 2일 월요일
[SAF] 데이터분석 과정 2주차 - 기초 실습
#1 - 변수 값 할당
##대입연산자 <- 단축키 ( Alt + - )
a <- 1
x <- 3
print(a)
## [1] 1
print(x)
## [1] 3
#2 - 변수를 출력하는 방식 - print()
x <- c("TR", "MG", "SH", "KR")
print(x)
## [1] "TR" "MG" "SH" "KR"
#3 - 변수 연산
print(c(1*pi, 2*pi, 3*pi, 4*pi))
## [1] 3.142 6.283 9.425 12.566
#4 - 변수 논리값
c(TRUE, FALSE, TRUE, FALSE)
## [1] TRUE FALSE TRUE FALSE
c(true, false, true)
## Error: 객체 'true'를 찾을 수 없습니다
#5 - 변수 결합
v1 <- c(1, 2, 3)
v2 <- c(4, 5, 6)
v3 <- c(v1, v2)
v3
## [1] 1 2 3 4 5 6
#6 - 수열
1:5
## [1] 1 2 3 4 5
b <- 2:10
b
## [1] 2 3 4 5 6 7 8 9 10
10:19
## [1] 10 11 12 13 14 15 16 17 18 19
19:10
## [1] 19 18 17 16 15 14 13 12 11 10
e <- 10:2
e
## [1] 10 9 8 7 6 5 4 3 2
#7 - seq(from=시작점, to=끝점, by=간격)
seq(from=0, to=20, by=2)
## [1] 0 2 4 6 8 10 12 14 16 18 20
seq(from=0, to=20, length.out=5)
## [1] 0 5 10 15 20
# 소수점의 표기가 있는 경우
seq(from=1.0, to=20.0, length.out=5)
## [1] 1.00 5.75 10.50 15.25 20.00
seq(0, 20, by=2)
## [1] 0 2 4 6 8 10 12 14 16 18 20
seq(0, 10, length=20)
## [1] 0.0000 0.5263 1.0526 1.5789 2.1053 2.6316 3.1579 3.6842
## [9] 4.2105 4.7368 5.2632 5.7895 6.3158 6.8421 7.3684 7.8947
## [17] 8.4211 8.9474 9.4737 10.0000
#8 - rep(반복할 내용, 반복할 수)
rep(1, time=5)
## [1] 1 1 1 1 1
rep(1:2, each=2)
## [1] 1 1 2 2
c <- 1:5
c
## [1] 1 2 3 4 5
rep(c,5)
## [1] 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
rep(c, each=5)
## [1] 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 4 4 4 4 4 5 5 5 5 5
#9 - paste(" 붙일 내용붙일 내용 " , sep= '''')
A <- c( " a" , "b" , "c")
A
## [1] " a" "b" "c"
paste( "a" , "b" , sep="")
## [1] "ab"
paste(A , c("d", "e"))
## [1] " a d" "b e" "c d"
f <- paste( A, 10)
f
## [1] " a 10" "b 10" "c 10"
paste(A , 10, sep= "")
## [1] " a10" "b10" "c10"
paste(A,1: 10, sep="_" )
## [1] " a_1" "b_2" "c_3" " a_4" "b_5" "c_6" " a_7" "b_8"
## [9] "c_9" " a_10"
paste("Everybody" , "loves" , "cats.")
## [1] "Everybody loves cats."
#10 - Substr(문자열 , 시작, 끝)
substr ("BigDat aAnalys i s" , 1,4)
## [1] "BigD"
ss <- c( "Moe ", "Larry", "Cur ly")
substr (ss , 1, 3)
## [1] "Moe" "Lar" "Cur"
#11 - 논리값 & 논리연산자
a <- 3
a == pi
## [1] FALSE
a != pi
## [1] TRUE
a < pi
## [1] TRUE
a <= pi
## [1] TRUE
a > pi
## [1] FALSE
a >= pi
## [1] FALSE
#12 - Matrix
# matrix( 이름, 행 수, 열 수)
# dim() 행렬의 행과 열 수를 반환
theData<- c(1.1, 1.2, 2.1, 2.2, 3.1,3.2)
mat<-matrix(theData ,2, 3)
mat
## [,1] [,2] [,3]
## [1,] 1.1 2.1 3.1
## [2,] 1.2 2.2 3.2
dim(mat)
## [1] 2 3
diag(mat)
## [1] 1.1 2.2
#diag( 행렬) 행렬의 대 각선 에 있는 값을 반환
#t() Matrix Transpose
t(mat)
## [,1] [,2]
## [1,] 1.1 1.2
## [2,] 2.1 2.2
## [3,] 3.1 3.2
help(t)
## starting httpd help server ... done
# colnamesO 열 네임을 조회
# rownamesO 행 네임을 조회
mat
## [,1] [,2] [,3]
## [1,] 1.1 2.1 3.1
## [2,] 1.2 2.2 3.2
colnames(mat) <- c(" IBM" , "MS", "GOOGLE" )
rownames(mat) <- c( "IBM" , "MS")
mat[1,] #첫째 행
## IBM MS GOOGLE
## 1.1 2.1 3.1
mat[,3] #셋째 열
## IBM MS
## 3.1 3.2
A <- matrix(0, 4,5)
A <- matrix(1:20 ,4, 5)
A
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 5 9 13 17
## [2,] 2 6 10 14 18
## [3,] 3 7 11 15 19
## [4,] 4 8 12 16 20
#1행, 4행, 2열, 3열 조회
A[c(1, 4), c(2, 3)]
## [,1] [,2]
## [1,] 5 9
## [2,] 8 12
#값을 대체
A[c(1 , 4) , c(2 ,3)] <- 1
#13 - List() 리스트에서 원소들은 다른 모드
lst <- list(3.14, "Mode", c(1 , 1.2, 3), mean)
lst
## [[1]]
## [1] 3.14
##
## [[2]]
## [1] "Mode"
##
## [[3]]
## [1] 1.0 1.2 3.0
##
## [[4]]
## function (x, ...)
## UseMethod("mean")
## <bytecode: 0x00000000085711a0>
## <environment: namespace:base>
a <-1:10
b <- matrix(1:10, 2, 5)
c <- c("name1", "name2")
alst <- list(a=a , b=b , c=c)
alst
## $a
## [1] 1 2 3 4 5 6 7 8 9 10
##
## $b
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 3 5 7 9
## [2,] 2 4 6 8 10
##
## $c
## [1] "name1" "name2"
str(alst)
## List of 3
## $ a: int [1:10] 1 2 3 4 5 6 7 8 9 10
## $ b: int [1:2, 1:5] 1 2 3 4 5 6 7 8 9 10
## $ c: chr [1:2] "name1" "name2"
alst$a
## [1] 1 2 3 4 5 6 7 8 9 10
alst$b
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 3 5 7 9
## [2,] 2 4 6 8 10
alst$c
## [1] "name1" "name2"
alst[[1]]
## [1] 1 2 3 4 5 6 7 8 9 10
alst[[1]][[2]]
## [1] 2
#14 - Dataframe
a <- c(1 , 2, 4, 6, 3,4)
b <- c(6 , 4 , 2, 4, 3.2 , 4)
c <- c(7 , 6 , 4, 2, 5,6)
d <- c(2 , 4 , 3, 1, 5, 6)
e <- data.frame(a , b, c, d)
e
## a b c d
## 1 1 6.0 7 2
## 2 2 4.0 6 4
## 3 4 2.0 4 3
## 4 6 4.0 2 1
## 5 3 3.2 5 5
## 6 4 4.0 6 6
# rbind(dfrml, dfrm2) 두 데이터 프레임의 행을 추가 할 때 사용
# cbind(dfrml, dfrm2) 두 데이터 프레임의 열을 추가 할 때 사용
data(iris)
head(iris)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
newRow <- data.frame (Sepal.Length=3.0, Sepal.Width=3.2, Petal.Length=1.6, Petal.Width=0.3, Species="newsetosa")
newRow
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 3 3.2 1.6 0.3 newsetosa
iris <- rbind(iris , newRow)
iris
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5.0 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## 11 5.4 3.7 1.5 0.2 setosa
## 12 4.8 3.4 1.6 0.2 setosa
## 13 4.8 3.0 1.4 0.1 setosa
## 14 4.3 3.0 1.1 0.1 setosa
## 15 5.8 4.0 1.2 0.2 setosa
## 16 5.7 4.4 1.5 0.4 setosa
## 17 5.4 3.9 1.3 0.4 setosa
## 18 5.1 3.5 1.4 0.3 setosa
## 19 5.7 3.8 1.7 0.3 setosa
## 20 5.1 3.8 1.5 0.3 setosa
## 21 5.4 3.4 1.7 0.2 setosa
## 22 5.1 3.7 1.5 0.4 setosa
## 23 4.6 3.6 1.0 0.2 setosa
## 24 5.1 3.3 1.7 0.5 setosa
## 25 4.8 3.4 1.9 0.2 setosa
## 26 5.0 3.0 1.6 0.2 setosa
## 27 5.0 3.4 1.6 0.4 setosa
## 28 5.2 3.5 1.5 0.2 setosa
## 29 5.2 3.4 1.4 0.2 setosa
## 30 4.7 3.2 1.6 0.2 setosa
## 31 4.8 3.1 1.6 0.2 setosa
## 32 5.4 3.4 1.5 0.4 setosa
## 33 5.2 4.1 1.5 0.1 setosa
## 34 5.5 4.2 1.4 0.2 setosa
## 35 4.9 3.1 1.5 0.2 setosa
## 36 5.0 3.2 1.2 0.2 setosa
## 37 5.5 3.5 1.3 0.2 setosa
## 38 4.9 3.6 1.4 0.1 setosa
## 39 4.4 3.0 1.3 0.2 setosa
## 40 5.1 3.4 1.5 0.2 setosa
## 41 5.0 3.5 1.3 0.3 setosa
## 42 4.5 2.3 1.3 0.3 setosa
## 43 4.4 3.2 1.3 0.2 setosa
## 44 5.0 3.5 1.6 0.6 setosa
## 45 5.1 3.8 1.9 0.4 setosa
## 46 4.8 3.0 1.4 0.3 setosa
## 47 5.1 3.8 1.6 0.2 setosa
## 48 4.6 3.2 1.4 0.2 setosa
## 49 5.3 3.7 1.5 0.2 setosa
## 50 5.0 3.3 1.4 0.2 setosa
## 51 7.0 3.2 4.7 1.4 versicolor
## 52 6.4 3.2 4.5 1.5 versicolor
## 53 6.9 3.1 4.9 1.5 versicolor
## 54 5.5 2.3 4.0 1.3 versicolor
## 55 6.5 2.8 4.6 1.5 versicolor
## 56 5.7 2.8 4.5 1.3 versicolor
## 57 6.3 3.3 4.7 1.6 versicolor
## 58 4.9 2.4 3.3 1.0 versicolor
## 59 6.6 2.9 4.6 1.3 versicolor
## 60 5.2 2.7 3.9 1.4 versicolor
## 61 5.0 2.0 3.5 1.0 versicolor
## 62 5.9 3.0 4.2 1.5 versicolor
## 63 6.0 2.2 4.0 1.0 versicolor
## 64 6.1 2.9 4.7 1.4 versicolor
## 65 5.6 2.9 3.6 1.3 versicolor
## 66 6.7 3.1 4.4 1.4 versicolor
## 67 5.6 3.0 4.5 1.5 versicolor
## 68 5.8 2.7 4.1 1.0 versicolor
## 69 6.2 2.2 4.5 1.5 versicolor
## 70 5.6 2.5 3.9 1.1 versicolor
## 71 5.9 3.2 4.8 1.8 versicolor
## 72 6.1 2.8 4.0 1.3 versicolor
## 73 6.3 2.5 4.9 1.5 versicolor
## 74 6.1 2.8 4.7 1.2 versicolor
## 75 6.4 2.9 4.3 1.3 versicolor
## 76 6.6 3.0 4.4 1.4 versicolor
## 77 6.8 2.8 4.8 1.4 versicolor
## 78 6.7 3.0 5.0 1.7 versicolor
## 79 6.0 2.9 4.5 1.5 versicolor
## 80 5.7 2.6 3.5 1.0 versicolor
## 81 5.5 2.4 3.8 1.1 versicolor
## 82 5.5 2.4 3.7 1.0 versicolor
## 83 5.8 2.7 3.9 1.2 versicolor
## 84 6.0 2.7 5.1 1.6 versicolor
## 85 5.4 3.0 4.5 1.5 versicolor
## 86 6.0 3.4 4.5 1.6 versicolor
## 87 6.7 3.1 4.7 1.5 versicolor
## 88 6.3 2.3 4.4 1.3 versicolor
## 89 5.6 3.0 4.1 1.3 versicolor
## 90 5.5 2.5 4.0 1.3 versicolor
## 91 5.5 2.6 4.4 1.2 versicolor
## 92 6.1 3.0 4.6 1.4 versicolor
## 93 5.8 2.6 4.0 1.2 versicolor
## 94 5.0 2.3 3.3 1.0 versicolor
## 95 5.6 2.7 4.2 1.3 versicolor
## 96 5.7 3.0 4.2 1.2 versicolor
## 97 5.7 2.9 4.2 1.3 versicolor
## 98 6.2 2.9 4.3 1.3 versicolor
## 99 5.1 2.5 3.0 1.1 versicolor
## 100 5.7 2.8 4.1 1.3 versicolor
## 101 6.3 3.3 6.0 2.5 virginica
## 102 5.8 2.7 5.1 1.9 virginica
## 103 7.1 3.0 5.9 2.1 virginica
## 104 6.3 2.9 5.6 1.8 virginica
## 105 6.5 3.0 5.8 2.2 virginica
## 106 7.6 3.0 6.6 2.1 virginica
## 107 4.9 2.5 4.5 1.7 virginica
## 108 7.3 2.9 6.3 1.8 virginica
## 109 6.7 2.5 5.8 1.8 virginica
## 110 7.2 3.6 6.1 2.5 virginica
## 111 6.5 3.2 5.1 2.0 virginica
## 112 6.4 2.7 5.3 1.9 virginica
## 113 6.8 3.0 5.5 2.1 virginica
## 114 5.7 2.5 5.0 2.0 virginica
## 115 5.8 2.8 5.1 2.4 virginica
## 116 6.4 3.2 5.3 2.3 virginica
## 117 6.5 3.0 5.5 1.8 virginica
## 118 7.7 3.8 6.7 2.2 virginica
## 119 7.7 2.6 6.9 2.3 virginica
## 120 6.0 2.2 5.0 1.5 virginica
## 121 6.9 3.2 5.7 2.3 virginica
## 122 5.6 2.8 4.9 2.0 virginica
## 123 7.7 2.8 6.7 2.0 virginica
## 124 6.3 2.7 4.9 1.8 virginica
## 125 6.7 3.3 5.7 2.1 virginica
## 126 7.2 3.2 6.0 1.8 virginica
## 127 6.2 2.8 4.8 1.8 virginica
## 128 6.1 3.0 4.9 1.8 virginica
## 129 6.4 2.8 5.6 2.1 virginica
## 130 7.2 3.0 5.8 1.6 virginica
## 131 7.4 2.8 6.1 1.9 virginica
## 132 7.9 3.8 6.4 2.0 virginica
## 133 6.4 2.8 5.6 2.2 virginica
## 134 6.3 2.8 5.1 1.5 virginica
## 135 6.1 2.6 5.6 1.4 virginica
## 136 7.7 3.0 6.1 2.3 virginica
## 137 6.3 3.4 5.6 2.4 virginica
## 138 6.4 3.1 5.5 1.8 virginica
## 139 6.0 3.0 4.8 1.8 virginica
## 140 6.9 3.1 5.4 2.1 virginica
## 141 6.7 3.1 5.6 2.4 virginica
## 142 6.9 3.1 5.1 "aperm" virginica
## 143 5.8 2.7 5.1 1.9 virginica
## 144 6.8 3.2 5.9 2.3 virginica
## 145 6.7 3.3 5.7 2.5 virginica
## 146 6.7 3.0 5.2 2.3 virginica
## 147 6.3 2.5 5.0 1.9 virginica
## 148 6.5 3.0 5.2 2.0 virginica
## 149 6.2 3.4 5.4 2.3 virginica
## 150 5.9 3.0 5.1 1.8 virginica
## 151 3.0 3.2 1.6 0.3 newsetosa
dim(iris)
## [1] 151 5
newcol <- 1:151
iris <- cbind(iris , newcol)
name <- c("john" , "peter" , "jennifer" )
gender <- factor (c( "m" , "m" , "f" ))
hw1 <- c(60, 60 ,80)
hw2 <- c( 40 , 50 ,30)
grades <- data.frame(name , gender , hw1 , hw2)
grades
## name gender hw1 hw2
## 1 john m 60 40
## 2 peter m 60 50
## 3 jennifer f 80 30
grades[1 , 2]
## [1] m
## Levels: f m
grades[ , "name"]
## [1] john peter jennifer
## Levels: jennifer john peter
grades$name
## [1] john peter jennifer
## Levels: jennifer john peter
grades[grades$gender=="m",]
## name gender hw1 hw2
## 1 john m 60 40
## 2 peter m 60 50
# subset(dataframe, select=열이름) : 데이터세 트에 서 조건에 맞는 내용을 조회
subset(iris , select=Species, subset=(Petal.Length> 1.7))
## Species
## 25 setosa
## 45 setosa
## 51 versicolor
## 52 versicolor
## 53 versicolor
## 54 versicolor
## 55 versicolor
## 56 versicolor
## 57 versicolor
## 58 versicolor
## 59 versicolor
## 60 versicolor
## 61 versicolor
## 62 versicolor
## 63 versicolor
## 64 versicolor
## 65 versicolor
## 66 versicolor
## 67 versicolor
## 68 versicolor
## 69 versicolor
## 70 versicolor
## 71 versicolor
## 72 versicolor
## 73 versicolor
## 74 versicolor
## 75 versicolor
## 76 versicolor
## 77 versicolor
## 78 versicolor
## 79 versicolor
## 80 versicolor
## 81 versicolor
## 82 versicolor
## 83 versicolor
## 84 versicolor
## 85 versicolor
## 86 versicolor
## 87 versicolor
## 88 versicolor
## 89 versicolor
## 90 versicolor
## 91 versicolor
## 92 versicolor
## 93 versicolor
## 94 versicolor
## 95 versicolor
## 96 versicolor
## 97 versicolor
## 98 versicolor
## 99 versicolor
## 100 versicolor
## 101 virginica
## 102 virginica
## 103 virginica
## 104 virginica
## 105 virginica
## 106 virginica
## 107 virginica
## 108 virginica
## 109 virginica
## 110 virginica
## 111 virginica
## 112 virginica
## 113 virginica
## 114 virginica
## 115 virginica
## 116 virginica
## 117 virginica
## 118 virginica
## 119 virginica
## 120 virginica
## 121 virginica
## 122 virginica
## 123 virginica
## 124 virginica
## 125 virginica
## 126 virginica
## 127 virginica
## 128 virginica
## 129 virginica
## 130 virginica
## 131 virginica
## 132 virginica
## 133 virginica
## 134 virginica
## 135 virginica
## 136 virginica
## 137 virginica
## 138 virginica
## 139 virginica
## 140 virginica
## 141 virginica
## 142 virginica
## 143 virginica
## 144 virginica
## 145 virginica
## 146 virginica
## 147 virginica
## 148 virginica
## 149 virginica
## 150 virginica
subset(iris, select=c(Sepal.Length, Petal.Length, Species), subset=c(Sepal.Width==3.0 & Petal.Width==0.2))
## Sepal.Length Petal.Length Species
## 2 4.9 1.4 setosa
## 26 5.0 1.6 setosa
## 39 4.4 1.3 setosa
#with(dataframe , 열 이름)
head(with(iris , Species))
## [1] setosa setosa setosa setosa setosa setosa
## Levels: setosa versicolor virginica newsetosa
help(with)
#merge(dfl, df2 , by="dfl와 df2의 공통된 열의 이름")
name<-c("TR", "MG", "SH", "PK")
year.born<-c(1995 , 2000, 2009, 2013)
place.born<-c ( "USA" , "KR" , "CHI" , "KR")
born <- data.frame(name, year.born, place.born)
born
## name year.born place.born
## 1 TR 1995 USA
## 2 MG 2000 KR
## 3 SH 2009 CHI
## 4 PK 2013 KR
name<-c("TR" , "MG" , "SH")
year.died<-c(2100 , 2300 , 2500)
died <- data.frame(name, year.died)
died
## name year.died
## 1 TR 2100
## 2 MG 2300
## 3 SH 2500
#데이터프레인 두가지를 이름 항목으로 조합하는 예
merge(born , died , by="name")
## name year.born place.born year.died
## 1 MG 2000 KR 2300
## 2 SH 2009 CHI 2500
## 3 TR 1995 USA 2100
help(merge)
#15 - Sample Source
install.packages("ggplot2")
## Error: trying to use CRAN without setting a mirror
library(ggplot2)
data(movies)
head(movies)
## title year length budget rating votes r1 r2 r3
## 1 $ 1971 121 NA 6.4 348 4.5 4.5 4.5
## 2 $1000 a Touchdown 1939 71 NA 6.0 20 0.0 14.5 4.5
## 3 $21 a Day Once a Month 1941 7 NA 8.2 5 0.0 0.0 0.0
## 4 $40,000 1996 70 NA 8.2 6 14.5 0.0 0.0
## 5 $50,000 Climax Show, The 1975 71 NA 3.4 17 24.5 4.5 0.0
## 6 $pent 2000 91 NA 4.3 45 4.5 4.5 4.5
## r4 r5 r6 r7 r8 r9 r10 mpaa Action Animation Comedy Drama
## 1 4.5 14.5 24.5 24.5 14.5 4.5 4.5 0 0 1 1
## 2 24.5 14.5 14.5 14.5 4.5 4.5 14.5 0 0 1 0
## 3 0.0 0.0 24.5 0.0 44.5 24.5 24.5 0 1 0 0
## 4 0.0 0.0 0.0 0.0 0.0 34.5 45.5 0 0 1 0
## 5 14.5 14.5 4.5 0.0 0.0 0.0 24.5 0 0 0 0
## 6 14.5 14.5 14.5 4.5 4.5 14.5 14.5 0 0 0 1
## Documentary Romance Short
## 1 0 0 0
## 2 0 0 0
## 3 0 0 1
## 4 0 0 0
## 5 0 0 0
## 6 0 0 0
#title 변수에서 skies가 들어간 행 + title , year, rating 변수열 6줄을 조회했다.
#grep(조회할 문자패 턴, data)
head( movies [grep("skies" , movies$title, ignore.case=T) ,c( "title" , "year" , "rating" )] )
## title year rating
## 38 'Neath Canadian Skies 1946 5.4
## 39 'Neath the Arizona Skies 1934 4.6
## 853 Ace Eli and Rodger of the Skies 1973 5.7
## 6512 Blue Montana Skies 1939 5.8
## 6527 Blue Skies 1946 6.3
## 6528 Blue Skies Again 1983 4.9
pattern = "^Summer.*?"
ndx <- grep(pattern , movies$title )
grep(pattern , movies$title )
## [1] 49825 49826 49827 49828 49829 49830 49831 49832 49833 49834 49835
## [12] 49836 49837 49838 49839 49840 49841 49842 49843 49844 49845 49846
## [23] 49847 49848 49849 49850 49851 49852 49853 49854 49855 49856 49857
## [34] 49858 49859 49860 49861 49862 49863 49864 49865 49866 49867 49868
## [45] 49869 49870 49871
head(movies[ndx , "title"])
## [1] "Summer" "Summer Blues" "Summer Camp"
## [4] "Summer Camp Girls" "Summer Camp Nightmare" "Summer Catch"
#벡터에 있는 원소 선택
fib<-c(0 , 1, 1, 2, 3, 5, 8, 13 , 21 , 34)
fib
## [1] 0 1 1 2 3 5 8 13 21 34
fib[1]
## [1] 0
fib[3]
## [1] 1
fib[1:3]
## [1] 0 1 1
fib[c(1 , 2, 4, 8)]
## [1] 0 1 2 13
fib[-1]
## [1] 1 1 2 3 5 8 13 21 34
fib[-c(1:3)]
## [1] 2 3 5 8 13 21 34
fib < 10
## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE
fib[fib<10]
## [1] 0 1 1 2 3 5 8
fib%%2==0
## [1] TRUE FALSE FALSE TRUE FALSE FALSE TRUE FALSE FALSE TRUE
fib[fib%%2==0]
## [1] 0 2 8 34
# as.data. frame(x): 데이터 프레임 형식으로 변환
# as.list(x) 리스트 형식으로 변환.
# as.matrix(x): 행 렬 형 식 으로 변환
# as.vector(x) 벡터 형식으로 변환
# as.factor(x): 팩터 (factor) 형식으로 변환
as.numeric("3.14")
## [1] 3.14
as.integer(3.14)
## [1] 3
as.numeric("Foo")
## Warning: 강제형변환에 의해 생성된 NA 입니다
## [1] NA
# NA or NULLL
as.character(101)
## [1] "101"
as.numeric(FALSE)
## [1] 0
as.numeric(TRUE)
## [1] 1
#문자열을 날짜로 변환
# Sys. Date(): 현재 날짜를 반환
# as.Date(): 날짜 객체로 변환
Sys.Date( )
## [1] "2014-06-02"
as.Date("2013-08-13")
## [1] "2013-08-13"
as.Date("08/13/2013")
## Error: character string is not in a standard unambiguous format
as.Date("08/13/2013", format="%m/%d/%Y")
## [1] "2013-08-13"
#날짜를 문자열로
#format(날짜, 포뱃)
as.Date("08/13/2013", format="%m/%d/%Y")
## [1] "2013-08-13"
format(Sys.Date())
## [1] "2014-06-02"
format(Sys.Date(), format="%m/%d/%Y")
## [1] "06/02/2014"
format(Sys.Date(), '%a')
## [1] "월"
format(Sys.Date(), '%b')
## [1] "6"
format(Sys.Date(), '%B')
## [1] "6월"
format(Sys.Date(), '%d')
## [1] "02"
format(Sys.Date(), '%m')
## [1] "06"
format(Sys.Date(), '%y')
## [1] "14"
format(Sys.Date(), '%Y')
## [1] "2014"
#Missing
a <- 0/0
a
## [1] NaN
is.nan(a)
## [1] TRUE
b <- log(0)
b
## [1] -Inf
is.finite(b)
## [1] FALSE
c <- c(0:4, NA)
is.na(c)
## [1] FALSE FALSE FALSE FALSE FALSE TRUE
# 데이터를 삭제 하는 rm()
rm(a)
rm(list=ls(all=TRUE))
data(iris)
summary(iris)
## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.30 Min. :2.00 Min. :1.00 Min. :0.1
## 1st Qu.:5.10 1st Qu.:2.80 1st Qu.:1.60 1st Qu.:0.3
## Median :5.80 Median :3.00 Median :4.35 Median :1.3
## Mean :5.84 Mean :3.06 Mean :3.76 Mean :1.2
## 3rd Qu.:6.40 3rd Qu.:3.30 3rd Qu.:5.10 3rd Qu.:1.8
## Max. :7.90 Max. :4.40 Max. :6.90 Max. :2.5
## Species
## setosa :50
## versicolor:50
## virginica :50
##
##
##
head(iris)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
head(iris, 10)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5.0 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
#install.packages("party")
#library(party)
# vignette("알고 싶은 package 이 름")
#vignette("party")
#q()
#Data 를 저장하고 읽어들이기
data(iris)
iris <- as.matrix(iris)
head(iris)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## [1,] "5.1" "3.5" "1.4" "0.2" "setosa"
## [2,] "4.9" "3.0" "1.4" "0.2" "setosa"
## [3,] "4.7" "3.2" "1.3" "0.2" "setosa"
## [4,] "4.6" "3.1" "1.5" "0.2" "setosa"
## [5,] "5.0" "3.6" "1.4" "0.2" "setosa"
## [6,] "5.4" "3.9" "1.7" "0.4" "setosa"
dim(iris)
## [1] 150 5
#setwd("D:/SysData/GoogleDrive/빅데이터/Education/SAF_Education/saf_example")
#rm(iris)
#write.csv(iris, file='iris.csv')
#iris <- read.csv("D:/SysData/GoogleDrive/빅데이터/Education/SAF_Education/saf_example/iris.csv")
#summary(iris)
#iris <- as.data.frame(iris)
#str(iris)
#a <- iris$Species
#save(a,file="exercise.Rdata")
피드 구독하기:
덧글 (Atom)
-
웹/앱 리뉴얼 프로젝트를 진행 중에 내부에서 처리해야할 프로세스상 로직이 있었는데 오라클(데이터베이스) 단계에서 처리가 곤란하게 되어 외부서비스(웹)의 특정 URL/URI를 호출해야 되는 경우가 생겼다. 구글링으로 검색을 해도 상세히 설명 된 곳이 별...
-
 다양한 채널의 블로그 작성으로 집중이 좀 안되기도 하고 나의 회사를 운영하고 관리 하다 보니 회사의 블로그로 작성 해보는 것은 어떤가 하고 하나로 옮겨 봅니다. (주)다이닝웨이브 - 블로그 바로가기
다양한 채널의 블로그 작성으로 집중이 좀 안되기도 하고 나의 회사를 운영하고 관리 하다 보니 회사의 블로그로 작성 해보는 것은 어떤가 하고 하나로 옮겨 봅니다. (주)다이닝웨이브 - 블로그 바로가기 -
전산실에서는 다양한 일들은 참으로 다양(방법)하게 처리 한다. 그러한 일중 자주 발생하지는 않지만 간혹 발생하는 것중에 하나가 사용자가 패스워드를 기억하지 못하는 경우가 있거나 패스워드를 알려주지 않고 퇴사 하는 경우가 간혹 있다. 물론 나이스한...